Sharing Our Passion for Technology
& Continuous Learning

This blog provides a recap of our talk delivered at the Iowa Technology Summit, and DevOpsDays Des Moines, and the Midwest Global AI Developer Days conferences.
We are publishing a three-part blog series that is a distillation of that talk; Intro to the Current State of AI/ML, Overcoming Challenges to Adoption, and Using AutoML.
About Us
Source Allies is an IT Consultancy founded in 2002 and driven by an Ownership Mindset. We’re Builders: Data Scientists, Engineers (Data, ML, Software, DevOps), Cloud Architects (AWS, Azure & GCP). We create innovative custom software products with our partners using the simplest architecture. Read more about our super-quants here and here.
Problem Statement
It is an exciting time to be interested in using AI/ML to innovate within your organization. The state of AI highlighted in Part 1 shows the rapid rate of advancement of AI, how it’s fueled by cloud and hardware acceleration.
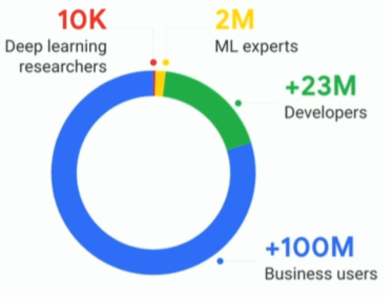
But there is a big problem standing in the way of ML and AI adoption which is the people part of the equation. There aren’t enough AI and ML experts to go around. We’re talking about 2M ML experts in total, compared to 23 Million developers and 100M business users.
The demand for those ML experts and data scientists has been growing by 74% annually according to LinkedIn which could translate into an arms race to try to hire those experts. That might make AI/ML out of reach of many organizations.
But what if we were able to quickly change the dynamics of this diagram and open up the space of AI/ML to developers and business users so they can get started and contribute on their own?
What if ML Were Accessible to 123M?

What if we could expand who could use these tools? If that were to happen, then we are potentially looking at increasing the number of people building ML models by 50 fold. Well, it’s possible today because of how much more approachable the space is thanks to recent innovations and tooling that allow more people to dabble in this space.
ML Scaling Options
If we take a step back and look at the scaling challenge more broadly, there are several avenues available to us to scale ML capabilities and we’ll touch on 3 of those options.
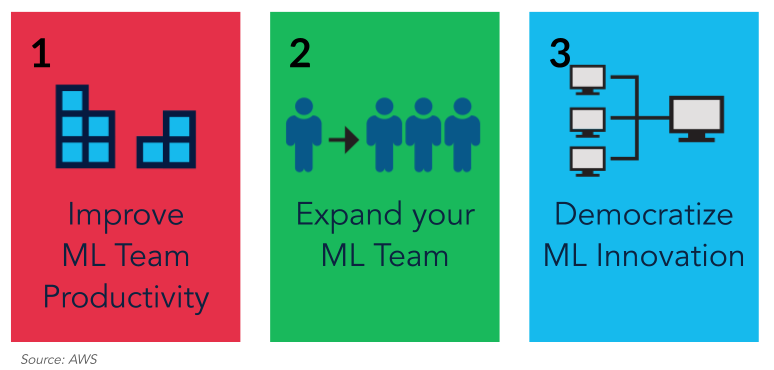
The first is to improve productivity by using ML building blocks that are available today instead of building models from scratch. You can also use prebuilt models. Another option is expand your team by hiring more data scientists, data engineers, ML/AI specialist engineers, and so. But let’s not forget that ML talent is in high demand today. According to LinkedIn demand is two times more than any other emerging field. The third option is to democratize the space with tooling that makes it more accessible not just to developers but also to business users.
Improving ML Team Productivity with AI Services / Building Blocks
The first option of improving productivity can be achieved with using ML building blocks that are available today instead of building models from scratch. You can also use prebuilt models. These AI/ML building blocks are available on all of the major cloud platforms to give your team a productivity boost. These help accelerate your effort because you’re taking advantage of typical cloud benefits (e.g. no upfront cost in building a data center or provisioning servers, and you take advantage of pay-as-you-go model), but more significantly, you don’t need to replicate all the work that went into building and refining these models over many years, and you can get a proof of concept up and running within hours instead of weeks.
Productivity of ML teams can also be increased by using the latest tools for explainability, data wrangling, debugging and profiling ML models, and DevOps tools for ML Models. For example, in the AWS platform, these are addressed in order by SageMaker Clarify, SageMaker Data Wrangler, SageMaker Debugger and SageMaker Pipelines.
Expanding Your ML Team
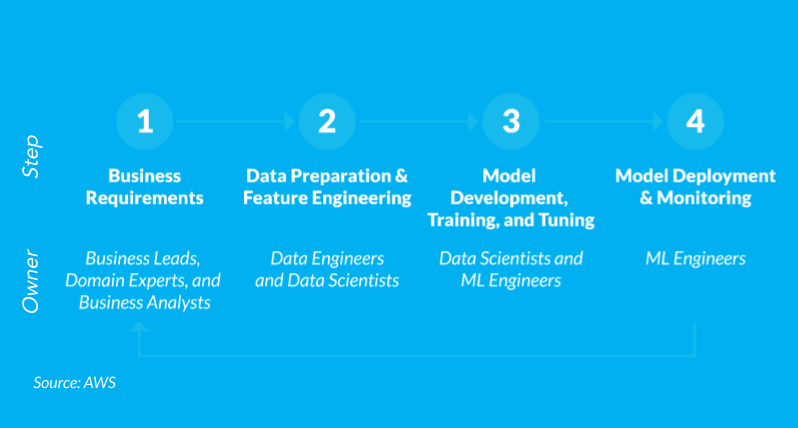
When talking about democratization of ML, its beneficial to look at what the process looks like today if you want to start an ML project. If you look at the typical ML model development and deployment process, you can break this down into four major phases. We start with business requirements, move to data prep and feature engineering, then model development and training and finally deploy the model and monitor it. And there is a feedback cycle that loops back as you learn more about how the model is behaving.
You'll notice that Data Scientists and ML Engineers are heavily involved in 3 of the 4 major phases. This becomes a resource constraint, especially in phase 3, because the experts are trying different combinations of feature engineering, hyper parameter tuning and model selection to get the best predictions. And again, based on the LinkedIn data about demand for those ML experts and data scientists growing by 74% annually, growing your ML team can be challenging.
Fortunately, there are AutoML tools that can give data scientists and ML engineers some time back by taking care of some of the tedius tuning process. There are also variations of these tools that support a high degree of collaboration between the business experts and the data scientists. Even with the advancements of AutoML tools, we still recommend some type of gating process between phases 3 and 4 so that we can leverage the deep expertise of data scientists and be cognizant of the safety and ethics considerations for the model under development. One of the big benefits of one of the AutoML tools we use in this series is that it supports the collaboration required to support having these guard rails in place.
Democratize ML Innovation
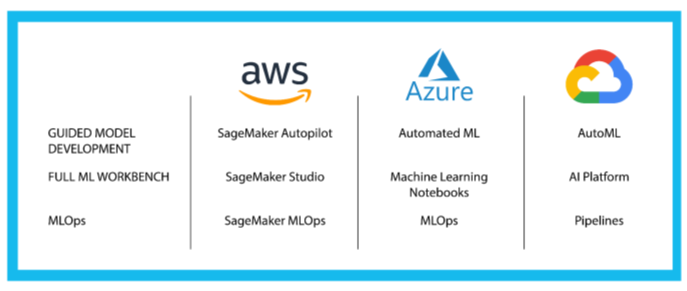
This democratization in the ML space is possible today thanks to a suite of tools available in all of the major cloud platforms called Guided Model Development.
We will focus on a couple of Guided Model Development tools called SageMaker Canvas and SageMaker Autopilot in the next part of this series. Canvas can be used by the business user, and the output from it can be can be analyzed by a data scientist in Autopilot. The basic idea behind these tools is that you can speed up and simplify the iteration on data prep, feature engineering, hyper parameter tuning, and model tuning. And getting those phases done without ML heavy-lifting. Not only does it make the process easier, but it also makes it faster. You can cut down weeks of work down to just hours.
There are also ML Workbench and MLOps tools that increases the productivity of the ML team but we won’t be going into details about them today. We do recommend you give them a look.
Website Builder Analogy
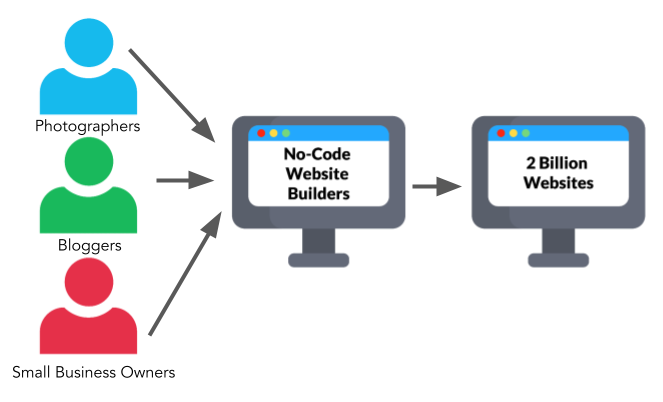
If we’re looking for an analogy to understand this democratization, we can say that Canvas is similar to website builders. Many of the websites that exist today were built by folks like small business owners, photographers and bloggers without needing to learn HTML or CSS. That was possible thanks to no-code website builders which allowed non-technical to build professional-looking websites without writing a single line of code.
Collaborative ML Industrialization
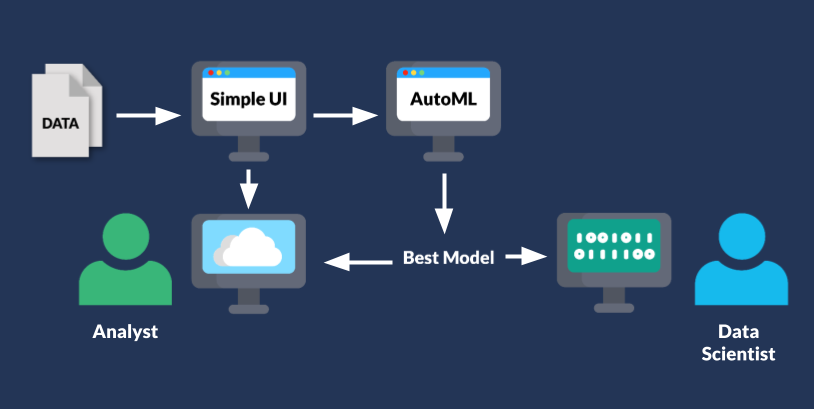
With the tools we're talking about, we have something very similar. On the left hand side, there is a simple user-interface (Canvas) that a business or data analyst can use by uploading their own data and then Canvas asks AutoML to iterate on different types of ML models, feature engineering and hyperparameter tuning to produce the best predictive model.
The business/data analyst is able to see how accurate the model is and then can share it with a data scientist or ML expert. The data scientist, on the right hand side of this diagram, can then "pop the hood" and look underneath at the details of how the model was built, analyze the specifics of the model, and ensure that model accuracy, loss, bias and safety are accounted for.
In other words, instead of the business/data analyst deploying the model, as in the classic website builder tooling, the analyst can instead share the model with the Data Scientist who will be able to analyze the model. This step builds trust and creates guardrails and governance process to ensure quality, soundness, explainability and ethics of the ML model. For example, the scientists can make sure that the model isn’t introducing bias.
ML Project Prioritization
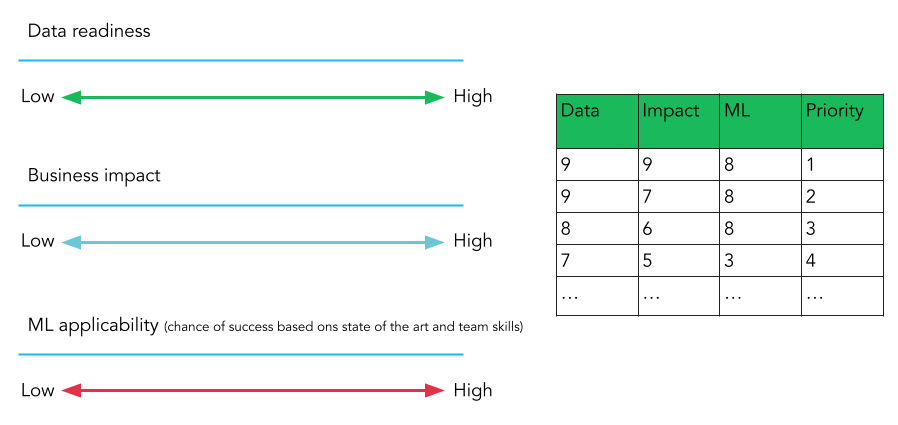
Another way we can use these kinds of tools is in project prioritization. A common rubrik for evaluating which project to prioritize spending time on is shown to the left. Projects are sorted by how ready the data is for analysis, what depth of impact the project will have, and the overall ML applicability given available tools and skills.
That third criterion has been a challenge in the past. It's a matter of figuring out of if the problem is solvable by ML, or asking the question "Is ML the right hammer for this nail?". Historically, this has been an educated judgement call by data scientists, but now you can load your data into a tool like Canvas, let it spin for a couple of hours, and see the results you get to help you with this assessment. If it performs great, it might be worth further investment. If it's performing poorly, then there might be better projects to focus time on. We'll revisit this in the next part of the series where we use AutoML.



