Sharing Our Passion for Technology
& Continuous Learning

The Iterative Migration: NoSQL to SQL
Gall’s law states that: “A complex system that works is invariably found to have evolved from a simple system that worked.” Maybe you’ve experienced this law when working on a system rewrite. Or perhaps you’ve felt the pain of working on a ticket that was too big, and the combined problems of scope creep and debugging were overwhelming. Source Allies practices extreme programming, which promotes short release cycles. Recently, my team used extreme programming techniques to complete a migration from a noSQL database (OpenSearch) to a SQL database (Postgres). Our iterative project design overcame the challenges of a complex migration, enabled us to tackle our “bad data” head-on, and empowered our team to be communicative, get feedback, and deliver on time.
The (data) problem
If you were performing a database migration, you’d ideally know the mappings for your source data; your data sources would provide values for required fields; and the foreign keys for your entities would be constant. Unfortunately, we had none of those luxuries. After years of processing data from multiple ERPs, our database models were rife with fields typed as {name?: string | null}. We had a known scenario that caused foreign keys to be altered, which made relationships across tables tenuous. And the integration mappings were incomplete, meaning we couldn’t always satisfy NOT NULL constraints, even when we did have definitions for all the required fields.
After months of coordination with data architects to design the database model, it was crucial to build momentum on the project. Designing an iterative migration allowed us to take the first step. We could begin on the infrastructure and invest in the technology and tooling that we’d need. We then could complete the migration a couple tables at a time, starting with those that the data architects had finished modeling. With each iteration, we identified specific blockers in the data and tracked them directly through story tickets. Focusing on migrating specific tables locked in progress, led to efficient planning and communication, and made defining our delivery timeline more practical.
In order to execute a successful migration system, we knew it had to be easy to run migrations, scale with new migration features, and monitor abnormalities in the data. Ideally, it would seamlessly transition from a migration database to a production database. Enter the system design: Kysely migrations, a custom Python command line framework (deployed in a lambda), SQS, OpenSearch and Postgres clients, a data issue logger, and an ever-expanding RDS database.
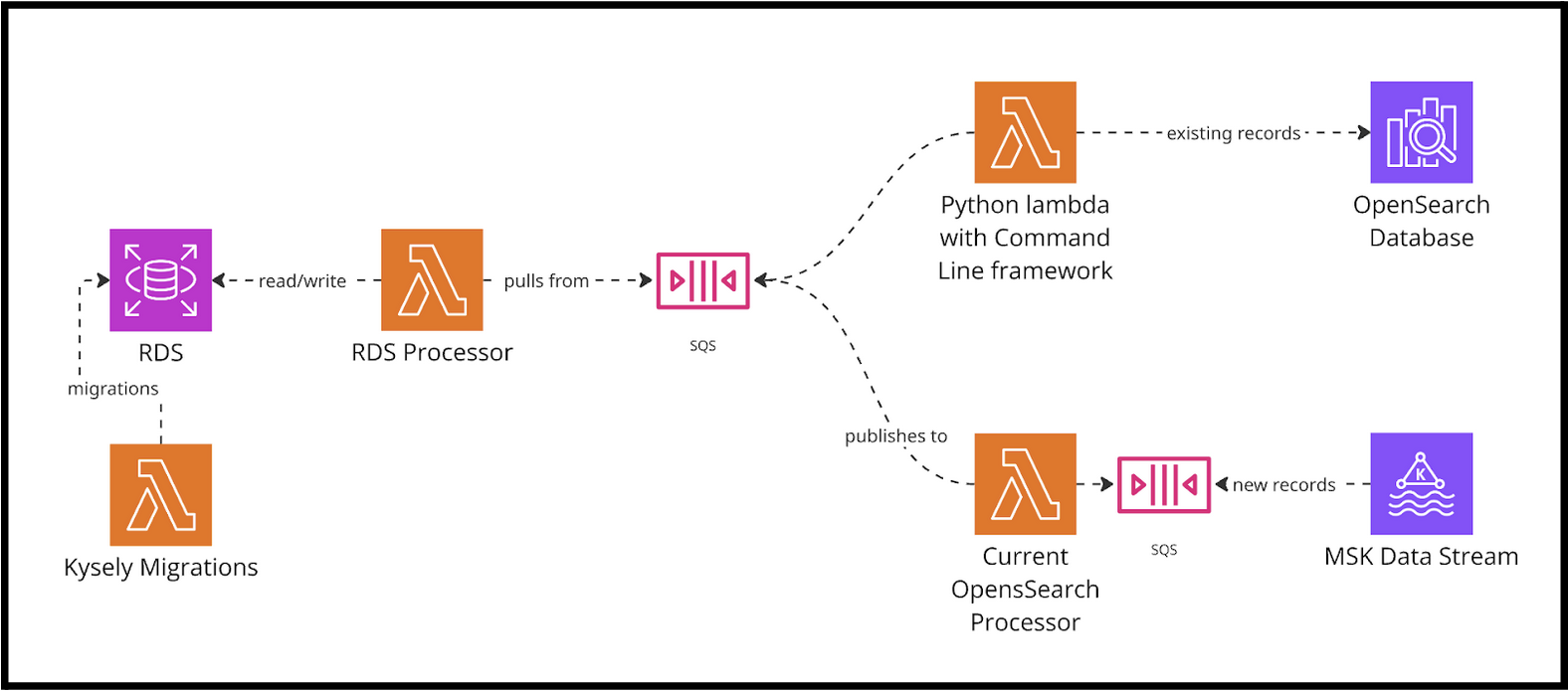
Iterative Migration: Architecture Diagram
Kysely migrations
CREATE TABLE bookshelf (book_id INT, title VARCHAR);
Before we began processing data, we needed to create the tables that would define our schema. Client-managed database migrations are a common way to ensure consistency across environments and allow reversions of database changes. We set up the deployment pipeline to run migration tasks by invoking a migration lambda, which used the Kysely client to execute SQL code, creating and updating tables as we progressed. With the core infrastructure in place, we were ready to begin work on the database. However, as we waited for some of the decisions around the data model to resolve, we decided to prioritize one more piece of our iterative infrastructure.
Python command line framework
yarn pyscript --env dev migrate_from_opensearch_to_postgres
An iterative migration needs iterations, so we needed a tool that could easily kick off migrations in any environment. We built a Python lambda that would serve us by reading the documents from OpenSearch and converting them to SQS messages to be processed and entered into Postgres. The command line framework was also built to scale for myriad new features: checking for parity across databases, polling and analyzing messages on the dead letter queue, and updating integration tables.
The lambda for our Python scripting framework accepted script commands as events, which it executed with access to both the RDS and OpenSearch databases. These scripts could also be invoked locally in any environment, which helped our team to get around timeout issues within the lambda.
In order to make the Python lambda flexible enough to suit a range of functions, yet structured enough to maintain consistency and readability, the framework provided developers with an interface for writing their own scripts. It leverages an argument parser which hooks into the script code before it executes, converting the command line arguments to parameters passed into the python code. To make these scripts easy for other teammates to use, the hooks also auto-generate "--help" content in the command line, informing users of accepted arguments and definitions. Three features of this scripting framework stand out:
- The design makes it easy to add new scripts
- The documentation makes it easy to use
- The configurations for connecting make it easy to connect to a range of AWS resources just by executing the script
SQS and the Processor Lambda
yarn pyscripts --env prd poll_dlq
Amazon's Simple Queue Service provided a tool that allowed us to accept incoming live data and maintain backwards compatibility. Our existing system already received data from SQS, converted it to our OpenSearch domain, and stored it in OpenSearch via bulk upload. To begin processing incoming data for our Postgres database, we sent the transformed objects as payloads directly to a secondary SQS. From there, we could begin writing code for the RDS processor lambda, transforming the OpenSearch document data from SQS and writing entries to the RDS tables. Before any migration occurred, the processor was already handling fresh incoming data just as it would after all the iterations were completed.
The same SQS queue was responsible for handling migration data. Messages from both sources (OpenSearch database and the OpenSearch subscriber lambda) came in after being transformed to the OpenSearch domain. This allowed us to process both new data and migration data with the same processor, meaning we could reach parity quicker. It does mean that one day we’ll need to rewrite the Postgres processor if we want to cut the code from the OpenSearch processor. It was a critical choice to take on some technical debt, one that allowed us to make immediate headway on the migration and ensure backwards compatibility with the existing system. Ultimately, the tech debt can be paid off iteratively as well, ensuring continual progress, flexibility, and delivery value.
Data Issues Handling
SELECT * FROM bookshelf WHERE author_id IS NULL;
The Postgres domain, being a relational schema with SQL constraints, enforced several data quality measures that were meant to leverage the schema to provide higher quality data to the rest of the organization. With each iteration we got closer to:
- Locking in unique and foreign keys–gaining control of our data to make it reliable
- Deliver data with integrity, guaranteeing certain fields would be defined and consistent–not just within our data product but across the organization
- Data that we could answer for if our clients had questions–all domain values are accounted for
Being the gatekeepers of the domain, while aiming for parity with the NoSQL system, meant that we needed to work closely with data teams to create integration tables, domain tables, and triage problematic data. After the initial phase of defining the tables and running migrations, we refactored the code to bring data issues to the top level of the processor. This meant that we could easily flag issues with the data, create conditional logic for attempting upserts, and notify the team of problems. If we were missing an ID for a certain domain value, the original message would be sent to the DLQ (dead letter queue) with an additional description of the issue and the problematic values. An alarm would notify us of any messages that arrived on the DLQ, so we could promptly reach out to the data source or the data architects to resolve the issue. The DLQ is an excellent resource for us, as it has a built-in way to add messages back on to the queue for re-processing once the problems are addressed.
The data issues are also recorded in specific tables, allowing us to go back and analyze them. Storing problematic data, such as inconsistencies across groupings, was another iterative element of the migration. While the data wasn't immediately able to meet the demands of the schema, we were able to document when we received "bad data," what it looked like, and report it out so that the publishers could address it. By taking responsibility for the data, we acted as a catalyst that provided the needed documentation and impetus to make changes at the critical points of data ownership.
Conclusion
SELECT * FROM bookshelf;
Gall’s law also includes an inverse thesis: “A complex system designed from scratch never works and cannot be made to work.” Based on our experience, there are many reasons why shipping the wholesale migration would have failed: analysis paralysis, hidden complexity in the data, long communication cycles, among many others. Ultimately, designing and programming the migration to be flexible, using an iterative process, has stretched our design, technical, and communication skills. It has been a learning opportunity which promises more challenges and potential for growth as we begin to leverage our database by migrating API endpoints and unlocking new services for our data product. Iterative development is a core value of Extreme Programming, and is embraced by Source Allies because it ensures continual progress and delivery. In this example, by focusing on the work we could do at any given moment, we made it possible to reach a state of data parity despite the flaws in the data. If you're interested in designing simple solutions to complicated problems, reach out to us to learn more about Source Allies: who we are, what we do, and how you could contribute.



