Nutch is a framework for building web-scale crawlers and search applications. It is free and Open Source and uses Lucene for the search and index component. Nutch is built on top of Lucene adding functionality to efficiently crawl the web or intranet. Now the most obvious question is “Why Nutch when there is Google for all our needs?”. Some of the reasons could be:
- >Highly modular architecture allowing developers to create plug-ins for media-type parsing, data retrieval and other features like clustering the search results.
- Transparency of ranking algorithms.
- The Google Mini appliance to index about 300,000 documents costs ~$10,000. Ready to invest?
- Learn how a search engine works and customize it!
- Add functionalities that Google hasn’t come up with.
- Document level authentication.
Nutch Architecture:</strong>
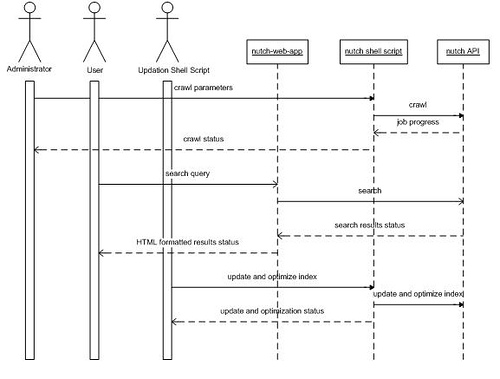
Data structures for a Nutch Crawl:
- Crawl Database or Sequence file:
<URL,metadata>- set of all URLs to be fetched. - Fetch List – subset of CrawlDB – URLs to be fetched in one batch.
- Segment – Folder containing all data related to one fetching batch. (Fetch list + fetched content + plain text version of content + anchor text + URLs of outlinks + protocol and document level metadata etc.)
- LinkDB –
<URL, inlinks>- contains inverted links.
Setting up Nutch to crawl and search:
- A shell script is used for creating and maintaining indexes.
- A search web application is used to perform search using keywords.
Step 1:
Download Nutch and extract to disk, say /home/ABC/nutch directory (NUTCH_HOME).
Step 2:
Download and set up a servlet container Apache Tomcat GlassFish server
Step 3:
Get a copy of the Nutch code
Step 4: Creating the index
The nutch ‘crawl’ command expects to be given a directory containing files that list all the root level urls to be crawled. So:
- 4.1: Create a 'urls' directory in $NUTCH_HOME.
- 4.2: Create files inside the urls folder with a set of seed urls from which all resources which need to be crawled can be reached.
- 4.3: Crawling Samba shared folders requires you to give the URL of the shared folder like smb://dnsname/nutch/PDFS/ and editing smb.properties file in $NUTCH_HOME/conf to reflect the properties of the shared folder.
- 4.4: Restrict set of URLs to be crawled/not by writing regular expressions in
$NUTCH_HOME/conf/crawl-urlfilter.txt and $NUTCH_HOME/conf/regex-urlfilter.txtExample:
+^(http|https)
-^(ftp|mailto)
+(pdf|html)$
-(jpeg|png)$
+^http://([a-z0-9\-A-Z]*\.)*sourceallies.com
-https://www.domainname.com/svn/project/tags
In the above regular expressions, + indicates crawl and - indicates do not crawl the URLs matching that pattern.
- 4.5: Including Plug-ins: Go to $NUTCH_HOME/conf/nutch-site.xml and name all the plug-ins required for your crawl as follows:
<property> <name>plugin.includes</name> <value> protocol-httpclient|protocol-smb|urlfilter-regex|parse-(pdf|html)|index-(basic|anchor| more)|query-(basic|site|url)|response-(json|xml)|summary-basic|scoring-opic|urlnormalizer-(pass|regex|basic) </value> </property>
- 4.6: Running the crawl:
$NUTCH_HOME/bin/nutch crawl urls -dir crawl.sai -depth 10
-dir dir names the directory to put the crawl in.
-depth depth indicates the link depth from the root page that should be crawled.
-delay determines the number of seconds between accesses to each host. -threads threads determines the number of threads that will fetch in parallel.
OUTPUT OF THE CRAWL:
A typical output after the Crawl command will be:
- A new directory named ‘crawl.sai’ in $NUTCH_HOME.
- NUTCH_HOME will contain the search index for the URLs.
- The ‘depth’ of the search index will be 10.
A search index in Nutch is represented in the file system as a directory. However, it is much more than that and is similar in functionality to a database. The nutch API will interact with this index making the internal mechanisms transparent to both developers and end-users.
Nutch Crawling internals: Just in case you would like to do the Nutch crawl using the internals of Nutch instead of using the crawl command, here are the steps:
- Inject – Step 2 is bootstrapped by injecting seed urls into CrawlDB.
- Loop:
- Update and merge segments – update segments with content, scores and links from the CrawlDB.
- Invert links - <document, keywords[]> to <keyword, documents[]> using segments and update LinkDB.
- Indexing – one index for each segment.
- Deduplication – pages at different URLs with same content removed. Details and syntax of these commands along with options used with can be found at http://wiki.apache.org/nutch/NutchTutorial
Generate – Generate URLs to fetch from CrawlDB.
Fetch – Fetches the URL content and writes to disk.
Parse – Reads raw fetched content, parses and stores result.
UpdateDB – Update CrawlDB with links from fetched pages.
Step 5:
Configuring the Nutch Web Application The search web application is included in your downloaded Nutch archive. The search web application needs to know where to find the indexes.
- Deploy the Nutch web application as the ROOT context.
- In the deployment directory, edit the \WEB-INF\classes\nutch-site.xml file.
<property> <name>searcher.dir </name> <value>/home/ABC/nutch/crawl.sai</value> </property>
- Restart the application server.
Step 6:
Running a Test Search:
Open a browser and type the Tomcat/Glassfish URL (say http://groker.sourceallies.com:8080/nutch/) and you should get a welcome screen where you can type in a keyword and start searching!
Step 7:
Maintaining the index Create a new shell script with Nutch’s internal commands.
- Commands, which set the environment (ex:JAVA_HOME).
- Commands to do the index updating: </ol>
- Generate
- Fetch
- Parse
- UpdateDB
- Invert links
- Index
- Deduplication
- Commands to optimize the updated index. - Merge segments.
Note that during the maintenance phase, we “DO NOT” inject urls.
![]() NOTE: Index optimization is necessary to prevent the index from becoming too large, which will eventually result in a ‘too many open files’ exception in Lucene.
NOTE: Index optimization is necessary to prevent the index from becoming too large, which will eventually result in a ‘too many open files’ exception in Lucene.
The exact command syntax can be viewed on the webpage for the latest version of Nutch http://wiki.apache.org/nutch/NutchTutorial.
Step 8:
Scheduling Index updates. The shell script created from the above step can be scheduled to be run periodically using a ‘cron’ job.
Step 9:
Improving Nutch with plug-ins Now that we have Nutch set up, the basic functionality provided by Nutch can be extended by writing plug-ins to perform many specific functions like
- Custom search – (say, Search by e-mail id) http://wiki.apache.org/nutch/HowToMakeCustomSearch
- Document level authentication – An idea that could be implemented is to index a “authentication level” meta field from every document and when a user sends a search query, return only the results for which this user has access permission. This can be done by using the query-filter plugin in Nutch. This is one feature that is not provided by Google appliances as a user can view a “cached copy” of files he may not have access to.

