Sharing Our Passion for Technology
& Continuous Learning
Nutch and Solr for Open source “Google-like” search??
This is a follow-up blog to Matt's earlier post on Open Source Enterprise Search
We all love Google don't we? Right from searching the web or the company intranet to searching internal source code, we just “google” everything. Now, won't it be more fun to do by yourself what Google does for you? And probably even change how google does few things for you?? And learning how Google does it for you? All that without having to spend $10k+ on appliances to do this for you? If this sounds exciting, read on and Welcome to Open source search using Lucene, OpenGrok, Nutch and Solr.
A quick introduction to what these are: Apache Lucene: An Open Source full-text information retrieval(IR) library written in Java. Luke: Diagnostic tool to access, display and modify existing Lucene indexes. Nutch: Open source Java implemented search engine built on top of Lucene. Solr: Lucene-based search server which scales better than Nutch for Enterprise level usage.
Our basic goal is to develop a full text search engine. Full text search refers to a technique for searching a computer-stored document or database wherein the search engine examines all of the words in every stored document as it tries to match search words supplied by the user.
Steps in Full text search:
- Indexing: Scan the text of all the documents and build a list of search terms, often called an index, but more correctly named a concordance or an “inverted index”.
<li><strong>Search:</strong> Perform a specific query, referring only to the index rather than the text of the original documents.
A way to understand inverted indexes is like a List of <term -> Documents[]>.
More about Lucene: Lucene is just the core of a search engine. As such, it does not include things like a web spider or parsers for different document formats. Instead these things need to be added by a developer who uses Lucene.
Lucene does not care about the source of the data, its format, or even its language, as long as you can convert it to text. This means you can use Lucene to index and search data stored in files: web pages on remote web servers, documents stored in local file systems, simple text files, Microsoft Word documents, HTML or PDF files, or any other format from which you can extract textual information.
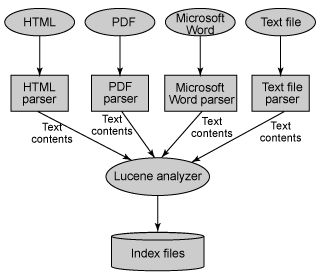
Lucene supports:
- Incremental indexing.
- Ranked searching.
- Wild card and proximity queries.
- Search by field (e.g., title, author, contents).
- Search by date range.
- Simultaneous update and search of index.
- Implementations available in other languages with the index being compatible!
Read more about the features and configuration details of Nutch and Solr in their specific blogs: Nutch - https://blogs.sourceallies.com/2009/10/nutch-features-and-configuration-details/ Solr - https://blogs.sourceallies.com/2009/10/solr-%E2%80%93-features-and-configuration-details/
Nutch Vs. Solr The Nutch crawler is ideal for crawling unstrucutred data such as PDF, Word Documents and HTML. It also has a feature-rich crawler(filters, authentication, not HTTP based like Solr). On the other hand, Solr is better for crawling Structured data such as XML, Databases etc and also scales better for Enterprise level search. Now the question is - Solr or Nutch? The solution:
- Use Nutch for indexing unstructured data.
- Use Solr for databases and structured data.
- Integrate both the indexes and use Solr to serve search results.
We will be (or at least I am) looking forward to a future when these Open source tools make it to a stage where people say “Just Solr it” instead of “Just Google it”. I believe the release of Solr1.4 after the release of Lucene2.9.1 will bring in many newer and better features and improve the popularity of open source search engines.



