Sharing Our Passion for Technology
& Continuous Learning

Fine-Tuning Can Wait: What Enterprise GenAI Really Needs
The Academic Bias Towards Model-Centric AI
Coming from an academic background, I was always taught that the best way to improve AI systems was by fine-tuning models or creating new, cutting-edge architectures. This was the core of many academic pursuits: better models lead to better performance. In research, the assumption was that you could iterate endlessly on models because you had access to well-curated datasets and virtually unlimited compute. The focus was almost always on model-centric AI, making the model better and better.
However, as I transitioned into real-world GenAI projects, it quickly became clear that this approach doesn’t always hold up. Real-world data is messy, unstructured, and often incomplete. Business environments demand results, not just the pursuit of the most advanced models. This shift in perspective was eye-opening. I realized that often, the model-centric mindset wasn’t the most practical or efficient solution.
Transition to Real-World Applications
Working on GenAI projects, I encountered the complexities of production environments. Rather than having clean, well-labeled datasets, we had to deal with noisy, incomplete, and sometimes contradictory data. It became apparent that instead of setting forth to spend time and resources on fine-tuning models, what we really needed was to build systems that could handle data imperfections and adapt to real-world conditions. I also realized that the focus on cutting-edge models might be great in a research context, but it’s not always aligned with the needs of enterprises that want scalable, cost-effective solutions. This was the moment when I learned: data-centric AI and system-centric AI are often far more effective than continually pushing for model-centric improvements. These approaches prioritize data quality and robust system design over complex models, making them far more practical in a production environment.
Data-Centric AI: The New Power Move
Over time, I came to realize that in many enterprise applications, the key to AI success isn’t more complex models, but better data. Data-centric AI focuses on improving the quality, labeling, and structure of the data fed into your models. In many cases, improving the data pipeline can deliver far greater performance boosts than continuing to tweak the model itself.
When you have control over your data, you can clean, enrich, and enhance it in ways that make the underlying models far more effective. In enterprise environments, where data is often fragmented or incomplete, focusing on improving data quality leads to quicker results, greater scalability, and more reliable outputs. The cost of improving data is generally lower than creating new models, and it can be a faster route to building effective, robust AI systems.
For example, in some of the GenAI projects I worked on, simply curating and cleaning the dataset led to noticeable improvements in model performance. It became clear that data-centric AI was the most efficient and cost-effective path forward for many enterprise use cases.
System-Centric AI: Building Robust Systems for the Real World
While improving data quality is essential, I quickly learned that even the best data can’t always solve all the challenges of deploying AI in real-world environments. This is where system-centric AI becomes crucial. In production, you often can’t control every aspect of your data, especially when you’re dealing with unstructured or external inputs (e.g., web scraping, customer support data, or even user-generated content).
For these kinds of applications, system-centric approaches focus on building robust, fault-tolerant systems that can handle noisy, incomplete, or incorrect data without failing. In these cases, it’s not about making the data perfect but about creating workflows and pipelines that can deal with imperfections.
For instance, retrieval-augmented generation (RAG) and multi-agent architectures are examples of system-centric designs that excel at processing imperfect data in real time. These systems use fallback mechanisms, reranking strategies, and feedback loops to ensure the AI provides reliable outputs, even when data quality is less than ideal. In fact, these system-centric strategies often lead to more resilient and scalable AI solutions in production environments.
Model-Centric AI: When Does It Make Sense?
Model-centric AI still has its place, especially when you’re working in environments that demand cutting-edge performance. If your goal is to push the boundaries of what AI can do, whether for research, benchmarks, or highly specialized tasks, fine-tuning models or creating new architectures is a powerful approach. However, this comes with a significant cost and complexity. It requires large, high-quality datasets, ongoing access to compute, and often incurs risks like overfitting or data leakage, which can complicate real-world deployment where privacy and security matter.
The cost extends beyond development. Hosting your own fine-tuned model typically means provisioning GPU-backed infrastructure that runs continuously, regardless of traffic. This makes the total cost of ownership 10 to 100 times higher than using a managed API, especially for enterprise workloads that are bursty or on-demand. Providers like OpenAI and Anthropic let you pay per request, making it more efficient to focus on better data and smarter retrieval pipelines instead of maintaining infrastructure.
Even in high-stakes enterprise applications, we’ve found that you can often reach 95-98% of your target accuracy without any fine-tuning at all. By first optimizing how your system retrieves and presents context through better data design and smarter retrieval pipelines, you can deliver strong results faster and cheaper. Fine-tuning should only enter the picture once evaluation shows those approaches have plateaued.
So, while model-centric AI is great for research or performance-focused projects, in the enterprise world, it is often not the most practical solution when time, budget, and security concerns come into play.
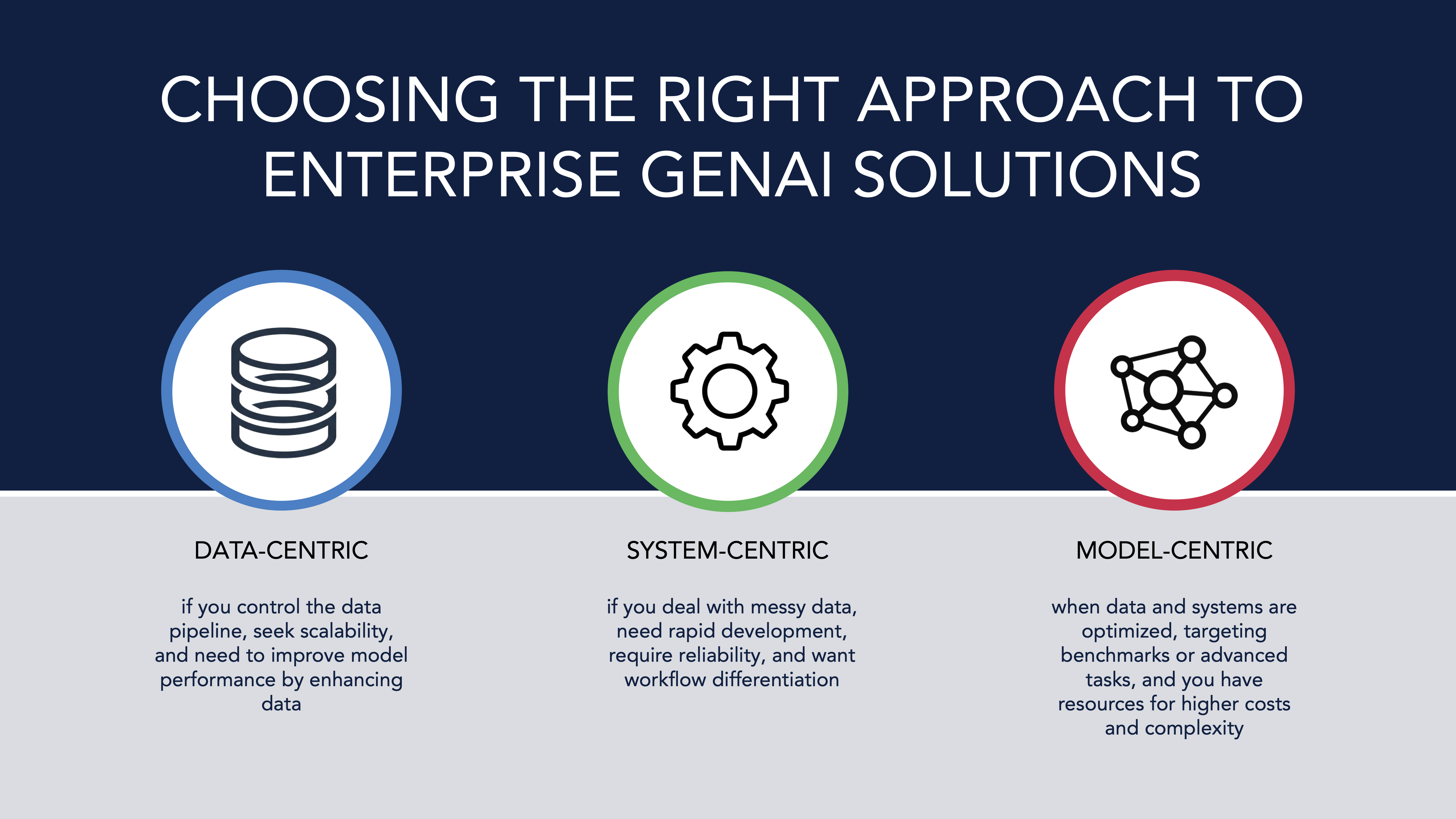
TL;DR: Choosing the Right Starting Point
- Start with Data-Centric if:
- You control the data pipeline and can clean, label, or structure it.
- You want long-term scalability and maintainability.
- You're hitting limits with model performance. Better data often helps more.
- Start with System-Centric if:
- You work with messy or external data (e.g., docs, web, user input)
- You need to move fast (POC phase or MVP)
- Reliability and robustness matter (e.g., chatbots, agents)
- You're aiming to differentiate with workflows, not just model output.
- Go Model-Centric only if:
- You’ve already optimized data and systems and still need performance gains.
- You’re targeting benchmarks or cutting-edge ML tasks.
- You have the resources to handle higher cost and complexity. Rule of thumb: Clean data scales. Smart systems adapt. Models come last, when everything else isn’t enough.
From Early Wins to Scalable Systems
In the end, model-centric AI still has a place, especially for cutting-edge research or highly specialized tasks. But in enterprise environments, data-centric AI and system-centric AI often lead to better ROI and are more practical when it comes to solving real-world problems.
Generally, enterprises shouldn’t jump into fine-tuning or model-centric work as a default. In most real-world cases, starting with data-centric or system-centric strategies is not only easier, but also faster and more cost-effective. Cleaning datasets, improving labeling, and designing robust retrieval pipelines or fallback systems typically unlock most of the needed performance. These routes deliver value quickly and align better with enterprise timelines. Evaluation should guide the next steps, and only when these foundational improvements plateau should model-centric investments be considered.
If you're building enterprise GenAI solutions, we encourage you to start with strategies that reduce risk, deliver early wins, and scale with clarity. At Source Allies, we help teams apply this system-and-data-first approach through production-grade retrieval systems, orchestration frameworks, and observability tools that show you when (and if) fine-tuning is actually worth it.
References
Data centric AI development From Big Data to Good Data Andrew Ng
RAG Agents in Prod: 10 Lessons We Learned — Douwe Kiela, creator of RAG



