Sharing Our Passion for Technology
& Continuous Learning

In our last post, we discussed the value provided by building custom Generative AI solutions as opposed to off-the-shelf solutions that claim to provide similar benefits. The reality is that 85% of Generative AI solutions are not in production, which can be attributed to a lack of trust or understanding in the technology. LLM evaluation metrics (Metrics) are the key to unlocking their full potential and building trust in an AI solution. They allow companies to join the 15% that do publish AI Applications to production with confidence.
In this blog post, we will discuss specific Metrics we have gravitated toward as a baseline for all Retrieval Augmented Generation (RAG) applications moving forward. These Metrics are measured using a combination of custom-developed solutions and Ragas, an open-source tool. As we continue to refine and improve RAG patterns, it is crucial to have a robust set of Metrics that allow us to measure the impact changes have on business outcomes. In this post, we'll explore the key Metrics powering our Metrics Driven Development (MDD) process that we've identified as a valuable baseline for assessing the effectiveness of any RAG solution.
Every chosen metric should be directly traceable to a business goal for the Generative AI Application - a common goal for most applications is for them to not generate responses that aren’t directly sourcable from the relevant documentation, called hallucinations, therefore the Faithfulness metric is the means to ensure the application is accomplishing this goal.
The Cornerstones of RAG Evaluation
1. Answer Correctness
What it is: A metric that measures how accurately the model's responses align with known correct answers, referred to as ground truth.
Value it provides: Ensures that the AI system is providing accurate and reliable information, which is crucial for building user trust and maintaining the system's credibility.
What to watch out for: This metric can be skewed if ground truth and answers are worded differently than one another, even if both are correct. It may misjudge comprehensive but accurate answers.
2. Answer Similarity
What it is: A metric that evaluates how closely the model's responses match the desired answers in style and approach.
Value it provides: Helps create a more natural and dependable interaction for users by ensuring the LLM's responses are consistent with how a subject matter expert may respond.
What to watch out for: Be cautious not to prioritize similarity over correctness. The value that GenAI provides must first and foremost be grounded in accuracy.
3. Faithfulness
What it is: A metric that assesses how well the model adheres to the facts within the reference documentation, provided as context, without introducing information that cannot be derived from context.
Value it provides: Helps prevent hallucinations present in the generated response, thereby improving the overall reliability of the answers.
What to watch out for: A high faithfulness score does not necessarily indicate that a complete answer was given or that all questions were answered. This metric only measures how often the LLM goes “off-script” from the contexts provided.
4. Context Relevancy
What it is: A metric that evaluates the quality of the information provided to the model for generating responses.
Value it provides: Ensures that the retrieval process is effective, providing the model with truly relevant reference documentation to work with.
What to watch out for: Be mindful that highly relevant context doesn't always guarantee a correct or useful response. The model's ability to utilize the context effectively is equally important.
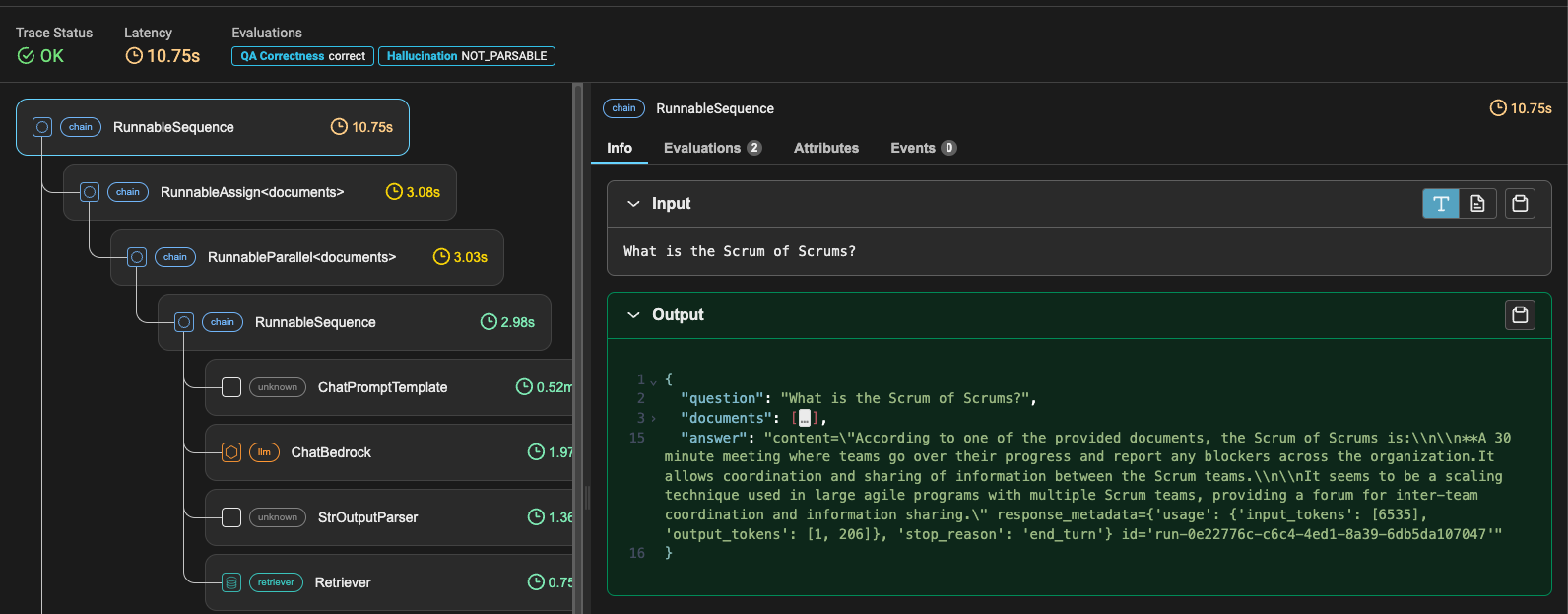
These Metrics are a great springboard to an RAG solution, however, they are not the end-all-be-all. These will provide a solid foundation when building a Generative AI solution. Additional Metrics may need to be added over time, depending on each use case.
Not All Metrics are Universally Applicable
While the core Metrics we discussed form a solid foundation for evaluating RAG solutions, it's essential to understand that not all Metrics apply universally to every use case. There are two main categories of evaluations:
- Foundation Model Evaluations: These are general-purpose Metrics that assess the overall performance of the model, such as accuracy, fluency, and coherence. They are applicable across various domains and provide a broad understanding of the model's capabilities.
- Domain-Specific Task Evaluations: These Metrics are tailored to specific tasks within a particular domain. They focus on how well the model performs in the context of specific business goals and requirements, such as adherence to industry regulations or alignment with company-specific guidelines.
For example, a metric like Aspect Critique, which assesses responses based on harmfulness or maliciousness, might be crucial for applications in sensitive areas like healthcare or finance but irrelevant for other domains. Implementing such specialized Metrics where they are not needed can waste development resources and create unnecessary complexity. It's important to select Metrics that align with the specific goals of your application and avoid redundant or irrelevant evaluations that may detract from the overall effectiveness of your Generative AI solution. By focusing on the most relevant Metrics, you can ensure a more efficient and impactful assessment process.
The Cost of Quality
Implementing robust Metrics comes with its own set of challenges, particularly when it comes to real-time evaluation. While real-time Metrics provide the most up-to-date performance insights, they can be costly to implement and maintain. On the other hand, scheduled, regimented evaluations of Metrics - against a known set of questions - offer a more cost-effective, reproducible, and reliable alternative.
The Value Proposition
In conclusion, the Metrics discussed form a comprehensive framework for evaluating our RAG solution, with each metric bringing its own unique value:
- Answer correctness builds trust in the system's outputs.
- Answer similarity ensures a consistent voice.
- Faithfulness safeguards against misinformation.
- Context relevancy validates the effectiveness of our retrieval process.
By implementing these Metrics, we're not just improving our Generative AI applications; we're enhancing the overall user experience, building trust, and ultimately delivering greater value to users. Metrics are the key to unlocking the full potential of GenerativeAI solutions.
In addition to the implementation of these Metrics themselves, we have accelerated our process with a set of jump-start tools. These tools allow teams to skip the tedium of starting from scratch and instead hit the ground running, gathering measurements and providing tangible value. Monitoring progress throughout the entire delivery cycle has allowed us to effectively deliver a series of metric-driven solutions that avoid common pitfalls that lead to Proof-of-Concept purgatory, which plagues 85% of AI applications.



