Sharing Our Passion for Technology
& Continuous Learning

Angular State Management Anti-Patterns
When looking at an Angular application, there are several powerful state management techniques available. There are built-in component bindings like the input and output bindings, services using RxJs and observables, and state management libraries like NgRx, Akita, MobX and NgXs. Well managed state can improve application performance and development velocity, while poorly managed state can introduce difficult-to-diagnose bugs, data inconsistencies, and memory leaks. By examining the common causes of bugs and development bottlenecks, coding patterns that are at the root of these issues begin to emerge. These patterns are called anti-patterns.
Anti-patterns are common solutions to problems that end up being bad ideas. These bad solutions are frequently arrived at because they are easy to use and typically work, but not without unintended consequences. They often arise from inexperience, lack of communication, or a misunderstanding of how the various state management tools are meant to be used.
In this article I will identify and discuss several anti-patterns to avoid in state management. While this article has an Angular focus, many of the concepts transcend framework and can be applied more broadly. Several of the antipatterns are specific to observables/RxJs, and others are more specific to the redux pattern or libraries that follow the redux pattern like NgRx. I will briefly discuss the anti-pattern, give examples, and offer solutions with links to other articles for a deeper understanding.
Anti-Pattern #1: State Duplication
The Problem:
When state is duplicated, the app loses its single source of truth. A single source of truth is important because it is the one place all code can look to find the most accurate information. When data is duplicated in the state object and the data does not match, components and services that rely on that data will have no way of knowing which data is accurate. This can lead to missed updates, inconsistent data, and race conditions between code that updates state for that data.
How Does it Happen? What Can we do?
State gets duplicated in several different ways. One of the most common code duplication pitfalls comes from using a collection of objects and storing off separate properties regarding single entities in that collection or properties of that collection.
For example, if the code requires a selected entity for updating, the impulse may be to store off the entire entity in a “selectedEntity” property. Once the entire entity is stored in the “selectedEntity” property, that data has been duplicated in the state object. This is called “Direct Entity Duplication”.

The solution is to store a reference to the entity in the collection and pull all details for that entity directly from the collection. This way all updates to that entity can be accurately reflected across the entire application.

Another common way to duplicate state is to store off a “totalEntities” property that is a count of the total number of entities in the collection. Since this count is simple to calculate and could easily change as other parts of the app add or remove entities from the collection, this property has a short shelf life for accuracy. This is called “Implicit State Duplication”.

The solution to this state duplication is to create a selector or a service that can calculate the count directly from the collection any time it has been requested.

For a more detailed explanation of State Duplication including more anti-patterns and clear code examples, visit this article by Minko Gechev.
Anti-Pattern #2: FrankenState
The Problem
When an application relies on more than one solution to manage state and it lacks clear boundaries between what data is managed where, it is easy to end up with a state management solution that is riddled with state duplications and data inconsistencies. This type of solution, which I call “FrankenState”, is difficult to develop against because of the confusing structure of the state object and the lack of a single source of truth.
How Does it Happen? What Can we do?
Frankenstate usually begins innocently enough. Typically a well meaning team brings in a new state management solution to help solve a problem or to “modernize” an application but neglects to set clear boundaries for the responsibility of this solution or to remove the previous solution. Examples of Frankenstate include bringing Apollo Client into an application that is already using NgRx, or creating separate stores for data in local components that contain data that is shared globally. Frankenstate can be exacerbated by teams independently using different solutions for state management that have overlapping data managed by each solution. There are some valid reasons to use more than one state management solution in an application, for example, using a local store for form data that is only ever used in one part of the application or for a global solution like authentication that can exist as a wholly separate unit of data. However, clear boundaries for how that data is accessed and what can change that data need to be drawn.
The solution to Frankenstate is careful planning at every step of the development process. While it is not always possible to plan for all of the state management needs of an application, it is possible to evaluate changing state management needs as they arise and make thoughtful decisions before adding to existing solutions.
Should the need to change solutions arise, developers should ask themselves three questions:
- What does this new solution do that my old solution cannot?
- What are the boundaries for what this solution will do?
- Will this solution replace the existing solution, and if not what is the strategy for how to approach shared data?
When planning for a new application, teams should ask:
- What is the main need for shared data in this application?
- Are there libraries or methods that handle this sort of problem better than others?
- What is my team familiar with and what is our capacity to learn/maintain a new solution?
Observables and RxJs
Observables are one of the most powerful state management tools built into the Angular framework. Using primitive observables, we can create relatively powerful state management solutions without importing any external libraries. Adding RxJs to observables gives a wide range of pipeable operators capable of shaping data and managing performance in an application. Unfamiliarity with observables or rxjs can lead to preventable mistakes that can cause difficult to diagnose issues in an application. The next three anti-patterns are directly related to observables and rxjs.
Anti-Pattern #3: Failure to Unsubscribe
The Problem:
When an observable is subscribed to, it will remain open until the stream completes or the observable is unsubscribed. Failing to unsubscribe from an observable when a component is destroyed will leave that subscription open. This leads to memory leaks in the application.
How Does it Happen? What Can we do?
Failing to unsubscribe usually happens because of inexperience with using subscriptions. As more and more subscriptions are added to an application, the more apparent memory leaks become.
The solution is to always unsubscribe. Luckily there are several different ways to unsubscribe from an observable. The most efficient solution is to take advantage of Angular’s async pipe in the component template. The async pipe handles subscribing on ngOnInit and unsubscribing on ngOnDestroy. It pushes change detection down into the template layer, and reduces a significant amount of code within the components which leads to easier testing and more code clarity. There are other methods for manually unsubscribing from an observable plus a detailed comparison of each of the methods in this article by Brian Love.
Anti-Pattern #4: Nested Subscriptions
The Problem:
A common scenario is to use values from one observable to retrieve values from another, for example, retrieving a customer and then using that customer to retrieve products purchased by that customer. A common mistake is to nest the subscription to retrieve products inside the subscribe method of the observable that returns the customer, this is a nested subscription. The problem with nesting subscriptions is that the first subscription has no control over the nested subscriptions. One very common result of this anti-pattern is that it sets up a race condition between the first subscription and the nested subscriptions which can lead to mismatched data between entities.

How Does it Happen? What Can we do?
This anti-pattern is very common amongst developers who are inexperienced with observables.
The solution to this anti-pattern is to spend some time getting to know the RxJs pipeable operators, specifically the transformation operators like mergeMap, concatMap, and switchMap. Using pipeable operators means the outer observable manages the inner observable, including subscribes and unsubscribes. The main benefit of managing subscriptions in this manner is since the outer observable manages the inner observable, there is no possibility of mismatched data. As new values come through the pipe from the outer observable, a new inner observable begins emitting for that new value. Each value in the outer observable has its own distinct inner observable. This protects against mismatched data and removes the race condition created by nesting subscribes inside other subscribes.

The following article by Yannick Baron has working code examples that clearly demonstrate how a race condition can occur and offers a solution to the problem.
Anti-Pattern #5: Stateful Streams
The Problem:
When variables are declared outside of a stream, the values those variables hold can be unreliable. For example if two events fire within milliseconds of each other and both rely on the same variable to hold values specific to that stream, this sets up a race condition that the first stream to set the variable needs to complete before the second stream changes that value.
How Does it Happen? What Can we do?
This anti-pattern is a common mistake developers make when they are unfamiliar with RxJs pipeable operators and they need to pass values from one step down through the stream along with subsequent values.
The solution is to use RxJs transformation operators, which can combine return values of multiple observables in a stream into a single response object. By keeping all values inside the pipe, these values are protected from unexpected outside influences. In fact using RxJs operators, it is possible to craft the exact response object needed by the end result of the stream. The RxJs docs offer a helpful Operator Decision Tree to help developers choose the right operator for their task. This is a useful tool to get to know new operators and to learn how to solve problems in a different way.
The following article by Yannick Baron discusses this anti-pattern more in depth and offers a code example with a solution for that example.
Redux Pattern
The last three anti-patterns I will discuss are directly related to the Redux Pattern or libraries that implement the Redux Pattern like NgRx.
Anti-Pattern #6: Sharing Redux Actions
The Problem:
When more than one component or service is capable of dispatching the same action and there is an unexpected dispatch of this action, it becomes a “Whodunit” mystery that can be difficult to solve.
How Does it Happen? What Can we do?
Sharing actions happens because as developers, we are programmed to reduce the lines of code in our applications; we strive to keep our code DRY. It can seem counterintuitive to create several actions that share the same result.
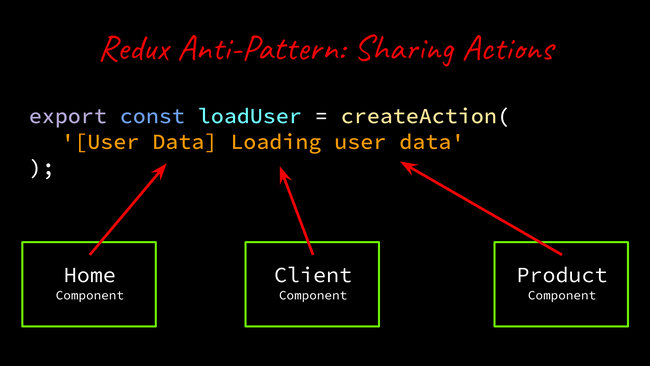
The solution is to shift our thinking to an event-driven style of programming, we then start to understand how to create unique actions that describe the event that has happened and react to that event instead of simply issuing commands. So a single action called “loadUser” can become several actions that result in the loading of the user but clearly defines the event that led up to this action. In NgRx, the “on” function in the reducers and the “ofType” operator for effects are capable of listening for a comma-separated list of actions. Separate actions triggered by different parts of the app can ultimately still trigger the same reducer or effect, and there will be a call sheet of actions that describe which components or services are capable of affecting that slice of state.

For a deeper understanding of good action hygiene, check out this talk given by Mike Ryan at NgConf 2018.
Anti-Pattern #7: Broad Selectors
The Problem:
Change detection in Angular is basically triggered by reference. Any time a new reference is handed down to a component, that component will rerender. While this is desirable for keeping the data displayed by an application up-to-date with the latest values, unnecessary rerenders can significantly slow down performance.
How Does it Happen? What Can we do?
By creating broad selectors that return large amounts of unnecessary state data, the odds that the component will experience unnecessary rerenders goes up. State management solutions like NgRx that offer memoized selectors can dramatically reduce the number of unnecessary component rerenders when used efficiently. Memoized selectors work by memoizing (remembering) the last emitted object. As new objects come into the selector, the selector does a property to property comparison of the new object against the old object. If nothing has changed, it discards the incoming object and instead emits the old object. Components compare the reference values for the existing and incoming objects and if they match, the component does not rerender.
The solution is to use composed selectors to return only the data required by the component. In addition to reducing the number of rerenders, composed selectors also reduce the amount of code inside of the component because the component no longer needs to have knowledge of the entire state object to be able to grab the values it cares about. Another beneficial side-effect is that there are less tests to write inside the component.
To hear a really great discussion about broad selectors and other NgRx related state management issues, listen to this episode of The Angular Show Pocast’s six-part series on State Management featuring Brandon Roberts.
Anti-Pattern #8: Monolithic NgRx Effects
The Problem:
The final anti-pattern I will cover is Monolithic NgRx Effects. The problem with a monolithic effect is that the code can become so convoluted that it is difficult to read, difficult to test, and difficult to onboard new developers.
How Does it Happen? What Can we do?
Monolithic effects are a common side effect of assuming that one action must trigger and complete all of the work it is meant to do inside one effect.

The solution is to break up the effect into smaller units of work that result in the dispatch of a new action that triggers the next effect to complete the next unit of work. This goes back to one of the tenets of clean codinghttps://medium.com/swlh/the-must-know-clean-code-principles-1371a14a2e75 where functions should really only do one thing.
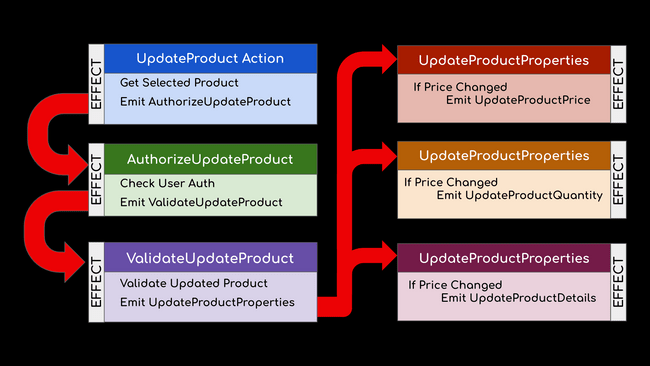
For example, consider that there is an action that is meant to trigger the update of a product, but needs to not only check user authorization, and validate the input, but may potentially need to update three different data stores. To write an effect that handles all of this work will result in an effect that merges several observables ( the authorization and validation checks with the original product update action), but then includes logic to determine if any of the three datastores related to the product need to be updated. A better solution would be to break this flow up into six different effects.
The initial effect will dispatch an action that triggers the authorization effect. The authorization effect can then dispatch an action that triggers the validation effect. Since more than one effect can be triggered by the same action as long as there is no expectation of synchronous completion of each of these events, the validation effect can dispatch an action that triggers the final three effects that each contain logic to determine which datastores need updated.
The result is that it is clear which unit of work each effect is performing, it is easier to read through the effects, and each effect becomes significantly more simple to test.
For more thoughts on this state management anti-pattern and other NgRx related antipatterns, listen to this episode of The Angular Show Podcast with guest Mike Ryan.
Conclusion
There are definitely other anti-patterns to look out for while managing state in Angular applications. With that said, being aware of the anti-patterns covered in this article and following through with the links provided is a great step to avoid common pitfalls and future frustrations. My general advice to anyone starting out with state management in Angular is to spend some time getting to know and understand RxJs pipeable operators. It is not necessary to understand every single operator or observable type in RxJs. In fact, there are many top ten style articles out there (like this one, or this one, or this one) that can help narrow down the hundreds of RxJs operators into a more manageable list to get started. Even experienced developers who spend most of their time using RxJs in Angular rarely reach outside of a couple dozen operators on a daily basis.
If you are looking for a good discussion on some of the RxJs operators, The Angular Show Podcast is starting a four part series on RxJs operators in November of 2020. You can hear more from me in the second part of the series about transformation operators. We discuss what some of the operators are, how and when they might be used, and pitfalls to avoid when using them. It’ll definitely be worth a listen!



