Sharing Our Passion for Technology
& Continuous Learning

The subject of this blog post is about Docker. Except, it's not really about Docker. It's about changing our mentality around our development environments. Specifically, about the way we haven't yet broken free of our old patterns in setting up our development machine. To borrow the adage, this post is about treating our development environments as cattle, not pets.
But first, let's talk about things that are hard.

The command line is hard. Yes, it is extremely powerful. Yes, learning the command line will give you a better understanding of the machine, but it is also a tool filled with inconsistencies, lack of discoverability, and vestigial behaviors. I find it ironic that the tech industry spends millions if not billions of dollars every year on usability research, yet we consider a black screen and a blinking cursor the premier interface for getting work done. But that's a different blog post.
Let’s talk about things that are hard.

Git is hard. The Brits will tell you that it's right in the name, and even Linus Torvalds himself is aware of its frustrations. Remember the first time you used Git? Remotes? Rebase? Staging Area?
Telling someone that Git is fundamentally a content-addressable filesystem with a version control user interface written on top doesn't help when you first see that your HEAD is in a detached state.
Let's talk about things that are hard.

Vim is hard. You can't even start coding right away when you first open Vim, which is a bold move for a text editor. No, you first need to enter insert mode. How many vimmers actually know how many modes Vim has? There are 7, or perhaps 14 if you count the mode variants. To give Vim credit though, it does have some of the best built-in documentation I've ever seen in a program, and I still remember how giddy I got when I realized I could make the spacebar my leader key. Yes, I'm a nerd.
So, what is one thing all these tools have in common? These are tools that are learned through practice.
Nobody got good at the command line, or Git, or Vim, simply by reading the documentation or from some innate ability. We learned these tools through practice, and we gained this practice by integrating these tools into our daily workflow. But why use these tools in the first place?
We use these tools because they fundamentally alter the way we work.
- We can solve new problems by gluing old programs together with the command line.
- Git provides great flexibility in the ways we collaborate with our fellow developers.
- We can edit and navigate text effortlessly in Vim by matching the brain's modality when coding.
And Docker allows us to isolate software from its environment. Certainly, the ops world is taking advantage of this benefit. We should be taking better advantage of it on the dev side as well.
However, like the command line, like Git, and like Vim, Docker is hard. We're probably aware of that lone Dockerfile sitting at the root of the repo. Perhaps we’ve opened it up and edited a few lines ourselves. Maybe we test our application locally with docker run. But when it comes time to start a new project or install new software on our development machine, I bet most of us fall back onto our old patterns.
Consider your organization's onboarding documentation. Or perhaps the README in a repo. What do I need to do before I can start working on the code?
Well, if we're using macOS, then setting up Homebrew is a common first step. On the Windows side there is Chocolately, although Microsoft has now announced an official command line package manager for Windows.
Okay, so our package manager is ready and we're working on a React application, which really means we need to install Node.js. But we can’t just install Node outright: we might be working on lots of projects, each of which requires its own version of Node! So, go ahead and pull down nvm, which you can use to install the correct version of Node. And instead of npm, maybe we’re using yarn to manage our node packages, so make sure to install that globally as well. And if you're not in the habit of running nvm use in the root of each repo you can apply some shell configurations to make sure it’s run automatically.
Now perhaps the backend is using .NET Core. Let’s do a quick Google search to find and download the necessary SDKs. Be mindful of that one repo that pinned the version using global.json.
Remember when Rails was setting the world on fire? We don't want to mess up our system Ruby, so let’s familiarize ourselves with rvm and rbenv. The data team's Python projects? Get comfy with virtualenv, pipenv, and pyenv. Oh right, half the org is using Java, so we’ll need to manage those SDKs either manually or with something like jabba or jEnv. And somehow PowerShell is un-cool even though there are tons of bash scripts passing structured data around using non-system tools like jq. Also, did you know there are some small behavior differences between the BSD version of UNIX shell tools on macOS and the GNU version of those tools on most Linux distros? Finding all the differences is left as an exercise for the reader.
When it's all said and done, hopefully nothing happens to your machine. You wouldn't want to start this whole process over again. And how much of this setup is accurately documented?
Now, I can't help but look at this and think: haven't we solved all this? On the worst days, it feels like my full-time job is being a system administrator of my own machine. I can deploy to production by pushing an image to a registry, but I need to manually download, configure, and maintain all my dev tools?
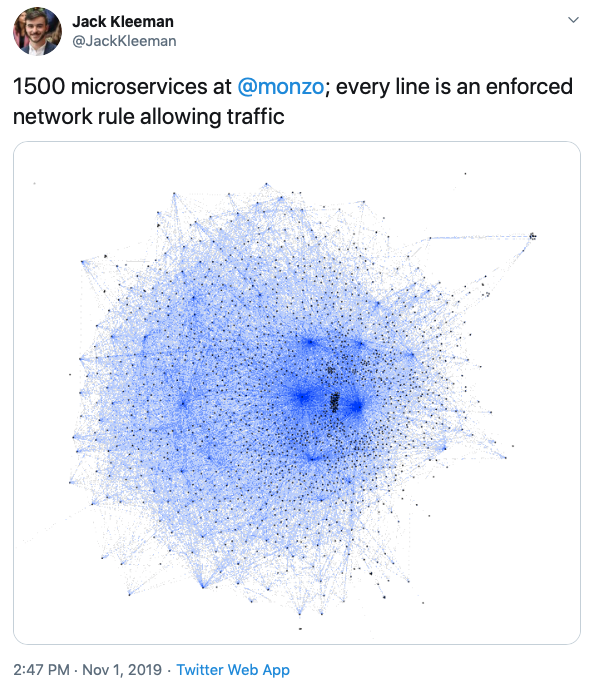
The above image comes from a tweet from a backend engineer at a banking company in the UK. I love this image. 1500 microservices! Ignoring the operational complexity, could you imagine having your machine ready to contribute to such a code base?
Alright, alright, it doesn't seem like every developer is contributing to every repo. Rather, there are 10 services to every 1 developer. And perhaps they're cheating a bit since it's all mostly Go. Still, what about the code that isn't mostly Go? Would someone be able to jump into an emergency bug fix? What if you're new to the team and that person is you?
I believe that the ability to consistently manage and deploy a dev environment is becoming increasingly important.
Let's consider the popular microservices architecture. By its very nature you'll have more repos to maintain compared to a monolith. Some teams have addressed this with a monorepo, but this practice doesn’t seem widely adopted. Or consider how much the industry is growing, both in head count and breadth of tools. And how globally we seem to have an append-only technology stack. COVID-19 did a great job of pointing out how much COBOL our society leans on. How many of us know how to get started with COBOL? How many of us know which tools to use when working with COBOL?
Let's do a better job of setting ourselves and future teammates up for success. Contributing to a repo ought to require little more than a git clone.

Personally, I'm tired of my machine being special. I want to take any box of compute and start getting to work. I don't want to care if it's Windows or Mac anymore, especially if I'm deploying to Linux at the end of the day. It might be a utilitarian view, but we’re paid to work together and solve problems. Our personal computers are incidental to the business goals.
Docker mostly replaced the need to manually install, configure, and maintain software on the server. With a simple docker build we can replicate our production application. In the next post , we will explore the following idea: what if we package our entire development environment into a container as well?



